THE PROBLEM
Client is a pharmaceutical company that specializes in the research and development of innovative healthcare products. The organization has multiple teams that develop and deploy machine learning models using different third-party platforms like Seldon, Kubecost, Argo etc. However, as the business grows, managing these pipelines becomes challenging in terms of scaling, data security, and complexity.
To address these problems, the client is building a centralized MLOps application using Python and GraphQL to handle the entire machine learning model lifecycle and uses Bitbucket as a code repository. Additionally, they have a model studio that works as a model registration space for the platform to ensure that each change in the model version and deployment is tracked properly. Consequently, anyone in the organization can collaborate in building and referencing ML models. However, the client wanted to introduce quality checking to ensure the performance and quality of the models being deployed in production across different platforms and scenarios. Hence, the client collaborated with Inxite Out.

INXITE OUT APPROACH
Model testing is an essential step in ensuring the quality and performance of a machine learning model. Best practices in model testing advise that model testing be done in two different stages of a pipeline: in the pre-training stage and the post-training stage. By conducting model testing in both stages, one can ensure that the model meets the desired objectives and expectations.
Pre-training stage
In the pre-training stage, the model testing focuses on validating the data quality, checking the assumptions and hypotheses, and verifying the feasibility and scalability of the model design. To ensure reproducibility and traceability, we version the data as it is used in training. We also perform different quality checks on the data as well as the model. These tests can be broadly divided into two following categories:
- Training data validation: Training data validation is where the data is processed for basic sanity checks and known issues. A common example of this includes making sure there are no missing labels in the data or percentages of missing values in the data. These tests ensure that the data being fed to the model passes the quality standard.
- Model design validation: Model design validation checks for sanity in the pre-processing steps of the ML model itself. The data is processed before it is used for training, where we need to make sure that our expectation (for example data range) is met in each step.
These checks are usually done using custom scripts, as different datasets may require different parameters to be tested. To expedite the testing process, a predefined format is adopted, but one can also add custom tests according to their specific needs.
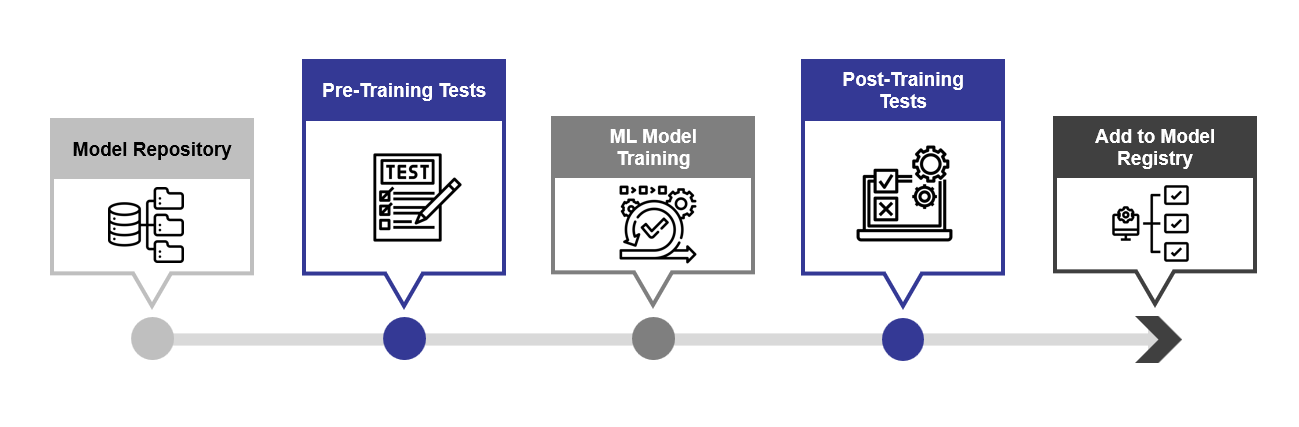
Post-training stage
In the post-training stage, model testing evaluates the accuracy, robustness, fairness, and generalization of the model on unseen data and scenarios. In short, we try to interrogate the logic learned during training and test if the model meets our expectations with its behaviour.
The tests implemented in the post-training phase are:
- Invariance test: One way to evaluate the robustness of a model is to introduce small changes in the input that should not alter the expected output. For example, changing the subject of a sentence (names) should not affect the output of sentiment analysis. These small changes are called perturbations, and they can be used as a benchmark to measure how consistent the model is. If the model produces different outputs for perturbed inputs, it indicates that the model is sensitive to irrelevant variations and may not generalize well to new data.
- Directional Expectation Tests: In this method we analyze the sensitivity and robustness of machine learning models by introducing perturbations to the input features that should have a predictable effect on the model output. For example, we expect that increasing the body temperature feature of a patient would increase the probability of a positive COVID-19 diagnosis by the model. If the model behaves otherwise, it may indicate a problem with the model training or the data quality. We use perturbations to measure how the model responds to different feature values and to identify potential sources of error or bias.
- Minimum Functionality Tests: Minimum Functionality Tests are a type of testing technique for machine learning models that aim to isolate and evaluate specific components or cases of the model. Unlike other testing methods that provide a holistic view of the model performance, Minimum Functionality Tests allow the developers to identify critical scenarios where prediction errors can have serious consequences. For example, when building a sentiment analysis model, the length of a sentence should not affect the prediction. A minimum functionality test would ensure that the model performs equally well for sentences with less than three words as for longer sentences.
RESULT
- Implemented solution achieved 30%+ reduction in machine learning model downtime in production through:
- Robust understanding of model behaviour during testing and detection of model inconsistencies
- Expedited analysis and fixing of detected errors.
- Improved understanding of model behaviour as versioning enabled benchmarking and comparison of different model versions with evolving configurations.

