
Share this Case Study
Automating Enterprise Data Operations: How an AI-Powered Portal Reduced Ingestion Time by 80%
Client Context
The client is a premier real estate institutional sales & marketing solution provider. Their core business relies on the rapid, accurate ingestion of customer lead data from various vendors, channel partners, and internal teams, making data availability a direct driver of revenue velocity.
However, legacy ingestion workflows were manual, fragmented, and difficult to scale, creating significant operational risks. Key challenges included:
- Multiple manual data insertions and limited automation across ingestion led to repetitive reconciliation of fields against backend database schemas.
- The handling of multiple file formats and the lack of standardisation resulted in significant manual overhead and operational delays.
- Operational oversight was hindered by the absence of transparent tracking and inadequate role-based access control.
Consequently, a scalable AI-powered Data Ingestion Platform was required to automate validation and field mapping, ensuring enterprise-grade governance.
The InXiteOut Approach
To address the challenges of scale and standardization, a scalable AI-powered Data Ingestion Platform was architected and deployed. The execution followed a structured three-stage process:
1. Diagnostic & Business Analysis
Before automation was applied, a comprehensive analysis of the client’s data ecosystem and ingestion workflows was conducted.
- Source Profiling: Historical vendor files were profiled to establish baseline schemas. This involved analyzing data from multiple vendors (credit bureaus, job portals, social media) and channel partners to understand the variety of incoming formats (CSV, Excel, JSON, APIs).
- Metadata Definition: Business requirements were mapped to define a "Mandatory Metadata" standard. This ensured that critical attributes, such as vendor posting date, data category, and campaign source, were captured consistently for every upload.
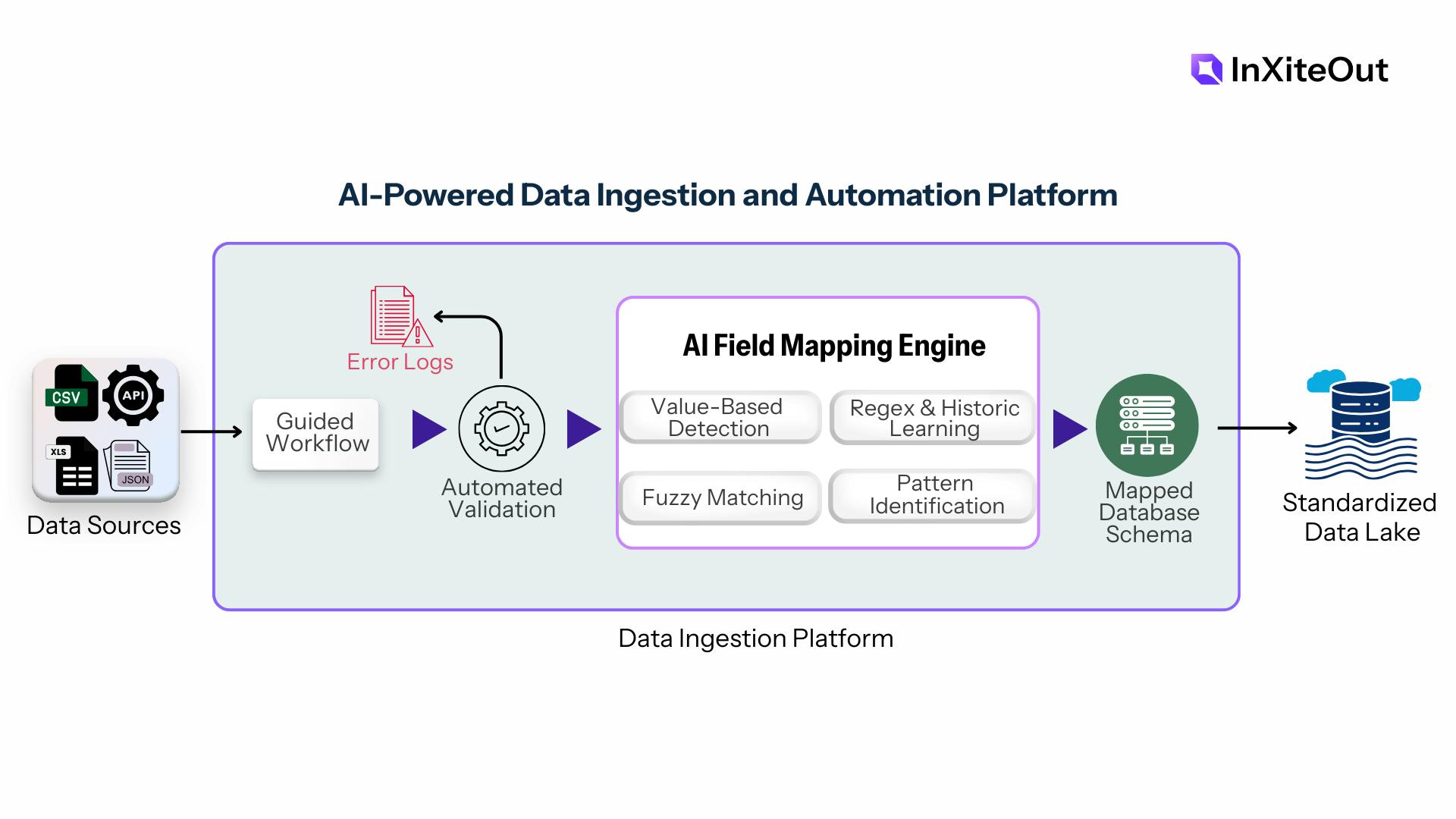
2. Data Upload Portal
A secure, MERN-based Data Upload Portal was developed to serve as the unified, self-service interface for all data providers.
- Guided Workflow: A three-step upload wizard was implemented to guide users through file selection, metadata entry, and validation.
- Automated Validation: Files are subjected to pre-processing checks immediately upon upload. Clear error logs are generated if format inconsistencies are detected, reducing the need for manual intervention.
- Role-Based Governance: A strict permission layer was built to manage admin approvals and user access, ensuring that only authorized personnel can map fields or approve new schemas.
3. The AI Field Mapping Engine
To eliminate manual reconciliation, a self-learning AI Field Mapping Service was engineered to automatically identify and map incoming columns to the database schema. The engine utilizes a multi-layered logic approach to handle variations in vendor data:
- Value-Based Detection: Ambiguous fields are mapped by analyzing the data content (e.g., detecting 6-digit integers for zip codes) rather than relying solely on headers.
- Regex & Historic Learning: Patterns such as email addresses are identified using regex checks combined with historical learning from previous uploads.
- Fuzzy Matching: Column naming variations (e.g., "name2" vs. "Surname") are resolved using fuzzy matching algorithms to ensure consistent mapping.
- Pattern Identification: Specific banking formats, such as IFSC codes, are automatically detected using regex and value-based identification.
Technology Stack
- Azure Data & ML Ecosystem: Azure Databricks, Azure Blob Storage (Data Lake).
- MERN Stack: React.js, Node.js, MongoDB.
Benefits Delivered
The platform delivered measurable business impact by accelerating data readiness, improving governance, and enabling faster downstream decision-making.
- 70–80% Reduction in Data Ingestion Time: The automated AI mapping and validation reduced the manual processing cycle from 2–6 hours per file to just 10–20 minutes.
- Zero Dependency on Backend Teams: New fields can now be created dynamically with admin approval, eliminating the need for engineering intervention to change schemas.
- 40–50% Faster Vendor Turnaround: Clear error logs and standardized templates reduced vendor-side rework cycles from 2–3 iterations to typically 0–1.
- 100% Elimination of Manual Checks: All manual template verification was replaced by automated validation logic, ensuring that only clean, compliant data enters the pipeline.
- Scalable Foundation: A modular architecture was established, creating a future-ready foundation for advanced capabilities such as real-time analytics without requiring architectural redesign.
- Enhanced Data Security: Sensitive enterprise data is protected through the implementation of Microsoft SSO and strict session controls.
Suggested Reads

Decoding the Commercial Vehicle Rejector: How Competitive Intelligence Reshaped an OEM's Strategy
Find out how AI-powered VoC analytics helped a global automotive OEM de-risk a major fuel tank design change, safeguarding sales and improving product decisions.

How MEGHNAD Insights Helped Optimize the Early Ownership Experience of a New Lifestyle SUV
Learn how MEGHNAD Insights empowered a top automaker to enhance SUV ownership quality, resolve early issues, and deliver a superior lifestyle experience.

Unstructured Voice to Strategic Insight: How InXiteOut Powers an Automotive Leader's Customer-First Strategy
Discover how InXiteOut transformed unstructured voice data into strategic insights, enabling a Fortune 500 automotive leader to accelerate customer-first decisions.
