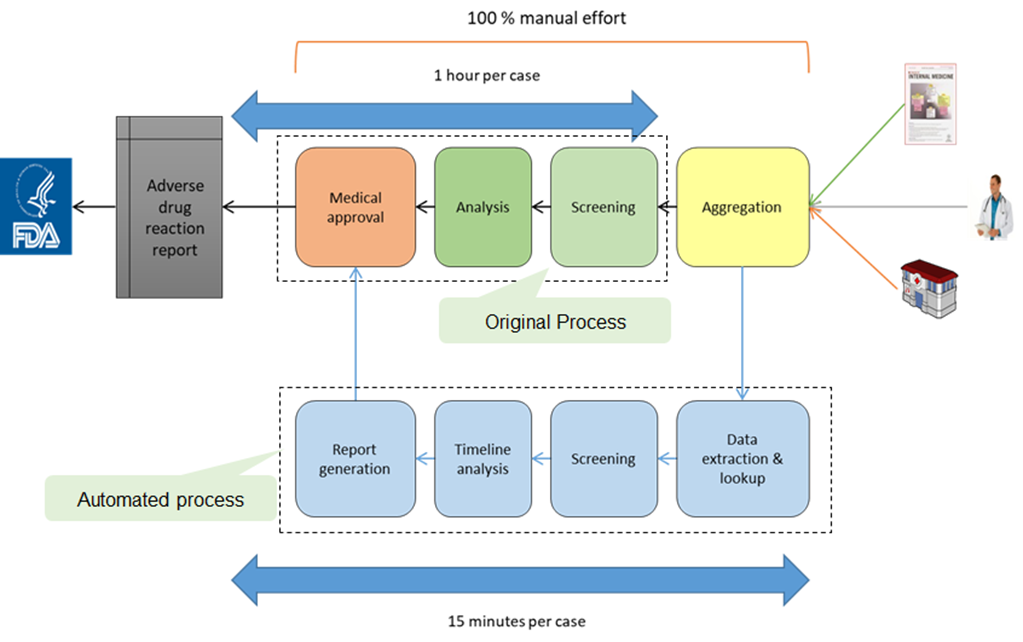
Natural Language Processing techniques were utilized to extract information from multiple structured and unstructured documents and aggregated in case file. Custom text processing techniques were used to parse and understand the structure of the documents and to consequently tokenize the text for further processing. Medical and Pharma dictionaries like MedDRA, WHO-DD, RxNorm, SNOMED-CT for Medical Coding & Disambiguation were further used to interpret the tokens in a medical context and to cluster the interpreted entities into relevant case files.