- May 25, 2023
- Posted by: sadmin
- Categories: Customers

What is CLIP?
“CLIP – Contrastive Language-Image Pre-training.”
CLIP is a multi-modal vision and language model. CLIP has learnt from unfiltered, highly varied, and highly noisy data, and is intended to be used in a ZERO-SHOT manner. CLIP is a significant step towards flexible and practical zero-shot computer vision classifiers.
While DALL-E creates images from text captions, for a wide range of concepts expressible in natural language, CLIP is a neural network, efficiently learns visual concepts from natural language supervision. CLIP has been built on a large body of work on zero-shot transfer, natural language supervision, and multi-modal learning. CLIP has learnt to recognize a wide variety of visual concepts in images and associate them with their names. Given an image, CLIP model can be instructed in natural language to predict the most relevant text snippet, without directly optimizing for the task, like the zero-shot capabilities of GPT-2 and 3.
Is Zero-shot CLIP competitive?
“Zero-shot CLIP is a new state of the art for image-classification”
On transfer learning, Zero-shot CLIP has outperformed few-shot linear probes. However, zero-shot CLIP notably underperforms, on several specialized, complex, or abstract tasks such as satellite image classification (EuroSAT and RESISC45), lymph node tumour detection (PatchCamelyon), counting objects in synthetic scenes (CLEVRCounts), self-driving related tasks such as German traffic sign recognition (GTSRB), recognizing distance to the nearest car (KITTI Distance).
On representation learning, models trained with CLIP scale very well and the largest trained model slightly outperforms the best performing existing model. CLIP’s features outperform the features of the best ImageNet model on a wide variety of datasets. Hence, Zero-shot CLIP models are expected to have much higher competitiveness and effective robustness.
Many of CLIP’s capabilities are omni-use in nature (e.g., OCR can be used to make scanned documents searchable, to power screen reading technologies, or to read license plates). Several of the capabilities measured, from action recognition, object classification, and geo-localization to facial emotion recognition, can be used in surveillance.
What are the advantages of CLIP?
- CLIP learns from text–image pairs that are already publicly available on the internet, hence it reduces the need for the expensive large and labelled datasets.
- CLIP can be adapted to perform a wide variety of visual classification tasks without needing additional training examples. To apply CLIP to a new task, all we need to do is “tell” CLIP’s text-encoder the names of the task’s visual concepts, and it will output a linear classifier of CLIP’s visual representations.
- As CLIP has learnt a wide range of visual concepts directly from natural language, CLIP models are significantly more flexible and general than existing ImageNet models.
What is CLIPPO?
“CLIPPO – CLIP-Pixels Only”
CLIPPO is a single Vision Transformer model that processes visual input, or text, or both together, all rendered as RGB images. CLIPPO understand images and language jointly using images as a sole input modality. The same model parameters are used for all modalities, including low-level feature processing; that is, there are no modality-specific initial convolutions, tokenization algorithms, or input embedding tables.
How is CLIPPO different from CLIP?
CLIP trains independent text and image towers via a contrastive loss i.e., CLIP trains separate image encoders and text encoders, each with a modality-specific pre-processing and embedding, on image/alt-text pairs with a contrastive objective. Whereas CLIPPO trains a pure pixel-based model with equivalent capabilities by rendering the alt-text as an image, encoding the resulting image pair using a shared vision encoder (in two separate forward passes), and applying same training objective as CLIP. CLIPPO uses a single encoder that processes both regular images and text rendered as images.
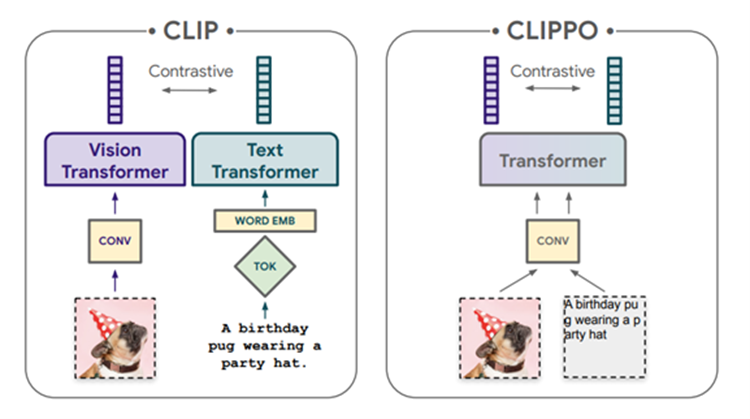
Functional difference between CLIP and CLIPPO
What are the advantages of CLIPPO?
- CLIPPO performs image-based tasks such as retrieval and zero-shot image classification almost as well as CLIP, with half the number of parameters and no text-specific tower or embedding.
- When trained jointly via image-text contrastive learning and next-sentence contrastive learning, CLIPPO can perform well on natural language understanding tasks, without any word-level loss (language modelling or masked language modelling), outperforming pixel-based prior work.
- CLIPPO can obtain good accuracy in visual question answering, simply by rendering the question and image together.
- CLIPPO does not require a tokenizer to show that it can achieve strong performance on multilingual multimodal retrieval without modifications.
- CLIPPO can perform complex language understanding tasks to a decent level without any left-to-right language modelling, masked language modelling, or explicit word-level losses.
- CLIPPO opens the door for additional modalities (e.g., spectrograms) that might inspire applications of pixel-only models beyond contrastive training.
- CLIPPO obtains strong multilingual image/text retrieval performance without requiring the development of an appropriate tokenizer.
Way Forward:
Models – CLIP/CLIPPO, trained via natural language supervision on a very large dataset are capable of high zero-shot performance. This line of work, focusing on richly connecting vision and language to solve complex downstream tasks such as visual question answering, visual common-sense reasoning, multi-modal entailment, OCR, action recognition in videos, Geo-localization, and many types of fine-grained object classification, is an opportunity to investigate further to characterize the capabilities of models and identify application areas where they have promising performance and where they may have reduced performance.
References:
- Learning Transferable Visual Models From Natural Language Supervision
- Hugging Face implementation of CLIP: for easier integration with the HF ecosystem.
- CLIPPO: Image-and-Language Understanding from Pixels Only